Data Trend: From Spreadsheets to Algorithms
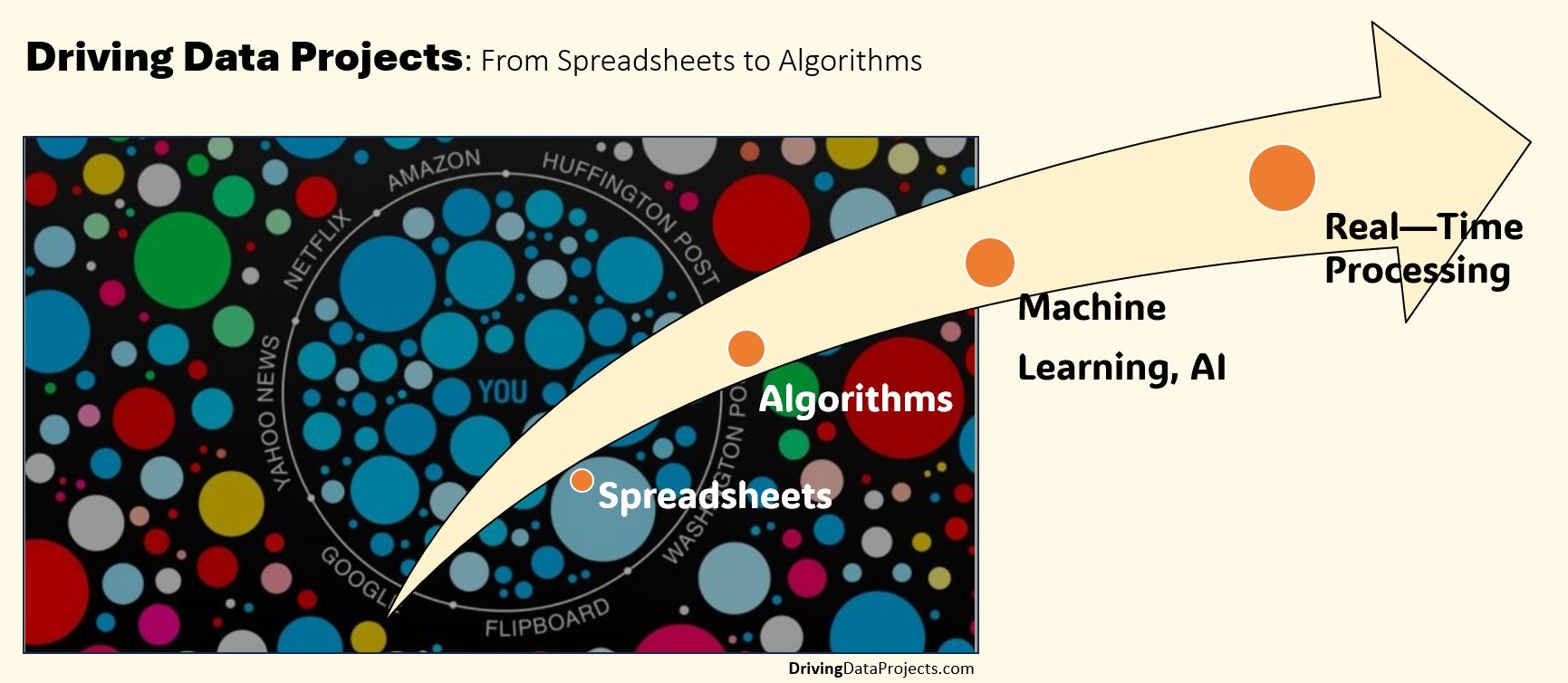
The transition from traditional spreadsheets to sophisticated data management and analysis algorithms represents a significant evolution that has revolutionized how businesses process and leverage information. Algorithms have reshaped the landscape of data-driven decision-making. Facebook's filter bubble is an early example of a machine learning system individualizing the user experience based on user patterns.
WHY SHOULD YOU CARE?
Because these design assumptions appear in everything from credit scoring to fraud prevention; it's no longer theoretical.
Data fluency in machine learning is knowing how to navigate, understand, and work with data throughout the entire data supply chain. It empowers individuals to make informed choices, interpret model behavior, and ensure the responsible and effective use of machine learning technologies.
Therefore, when discussing algorithms and AI, we must also discuss building AI Fluency in everyday people. EVERYONE needs to understand the impact and ethical considerations of sharing their data. It’s essential to understand the ethical and functional impacts of how AI is being applied to data so that people can advocate for themselves.
Visualizing the filter bubble. Credit: Pariser (2015) from Face the Bubble
🎯THE RISE AND LIMITATIONS OF SPREADSHEETS
In the early days of computing, spreadsheets provided a tool for organizing, calculating, and analyzing data. It set the foundation for data manipulation, offering a user-friendly interface for tasks ranging from budgeting to complex financial modeling. However, they were prone to errors, struggled with large datasets, lacked the capacity for intricate computations, and often "broke."
🎯ENTER ALGORITHMS
Algorithms represent an intelligent and automated approach to data analysis, uncovering patterns and insights that were once challenging to discern. Unlike spreadsheets, algorithms thrive on vast datasets, providing scalable solutions to complex problems.
🎯MACHINE LEARNING AND ARTIFICIAL INTELLIGENCE
Algorithms evolve with the integration of machine learning and AI. These technologies empower algorithms to learn, adapt, and make predictions with increasing accuracy, transforming decision-making processes.
🎯REAL-TIME DATA PROCESSING
Algorithms enable real-time data processing, enhancing agility and responsiveness in business decision-making.
🎯DATA SECURITY AND PRIVACY
Algorithms advance data security and privacy through encryption and privacy-preserving techniques, protecting sensitive information. Higher data quality yields a higher impact.
🎯CHALLENGES AND ETHICAL CONSIDERATIONS
As algorithms evolve, addressing biases and ensuring transparency in decision outcomes are ongoing challenges actively addressed by technology teams.
👉 THE FUTURE LANDSCAPE
Anticipate more sophisticated algorithms, integration with quantum computing, and the evolution of ethical frameworks to guide responsible data use.
DATA FLUENCY IN A MACHINE-LEARNING CONTEXT
According to Gartner, data fluency is the ability to read, write, and communicate data in context, including an understanding of data sources and constructs, analytical methods and techniques applied, and the ability to describe the use case, application, and resulting value. Due to the intricate nature of the processes involved, data fluency becomes crucial in machine learning. Machine learning relies heavily on data to train models, make predictions, and uncover patterns.
Here's why data fluency is essential in understanding the nuances of machine learning:
Interpretation of Data Inputs: Machine learning algorithms work with vast datasets, and being data fluent allows individuals to interpret the characteristics, features, and patterns present in these inputs. Understanding the nature of the data used helps grasp how machine learning models learn and make predictions.
Data Preprocessing: Before feeding data into machine learning models, preprocessing is often required to clean, transform, and organize the data appropriately. Data fluency ensures an understanding of preprocessing steps, such as handling missing values, scaling features, or encoding categorical variables, significantly impacting model performance.
Feature Selection and Engineering: Data fluency aids in identifying relevant features that contribute to the learning process. It involves selecting and creating features that enhance the model's ability to generalize patterns from the data. Fluency in data allows for informed decisions on which features are most valuable for a particular machine-learning task.
Evaluation of Model Performance: To assess the effectiveness of machine learning models, individuals need to be fluent in interpreting performance metrics. Data fluency enables a deeper understanding of metrics such as accuracy, precision, recall, and F1 score, providing insights into how well a model generalizes to new, unseen data.
Identification of Bias and Fairness Concerns: Machine learning models can inadvertently perpetuate biases in the training data. Data fluency allows individuals to recognize potential biases, understand fairness considerations, and take steps to address or mitigate these issues, ensuring ethical and responsible use of machine learning.
Decision-Making Based on Model Outputs: Machine learning models influence decision-making processes in many applications. Data fluency is essential for interpreting these models' outputs, understanding their implications, and making informed decisions based on the predictions or recommendations provided.
Data fluency in machine learning is knowing how to navigate, understand, and work with data throughout the entire data supply chain. It empowers individuals to make informed choices, interpret model behavior, and ensure the responsible and effective use of machine learning technologies.
3 REAL-WORLD EXAMPLES
Healthcare Diagnostics and Treatment Optimization:
Scenario: In healthcare, data fluency is crucial for medical professionals working with machine learning models to diagnose diseases and optimize treatment plans. Data fluency allows healthcare practitioners to interpret complex medical datasets, understand the features influencing predictions, and make informed decisions about patient care. For example, in oncology, understanding genetic data and interpreting machine learning predictions can aid in personalized treatment plans tailored to an individual's unique genetic profile.
Financial Fraud Detection and Prevention:
Scenario: Financial institutions rely on machine learning algorithms to detect and prevent fraudulent activities. Data fluency is essential for fraud analysts to comprehend transactional data, identify patterns indicative of fraudulent behavior, and fine-tune machine learning models. Data fluency enables professionals to interpret model outputs, adjust thresholds for alerts, and continuously improve fraud detection systems. This ensures timely and accurate identification of suspicious transactions, protecting both financial institutions and their customers.
E-commerce Customer Personalization:
Scenario: E-commerce platforms leverage machine learning to provide personalized shopping experiences for users. Data fluency is crucial for marketing and user experience teams to understand customer behavior, preferences, and purchasing patterns. Professionals with data fluency can interpret customer data, optimize recommendation algorithms, and enhance user interfaces. This leads to more accurate product recommendations, personalized marketing campaigns, and improved overall customer satisfaction, fostering long-term customer loyalty.
These real-world use cases highlight the importance of data fluency in various domains, where professionals use machine learning to extract valuable insights, make informed decisions, and deliver enhanced services or products.